Marco Mattiucci
Email me
2025-04-03 07:13:10
La sofferenza si dissolve quando comprendiamo la sua natura.
INFORMATICA
INTELLIGENZA ARTIFICIALE
TRIS (Tic Tac Toe) - gioco
Uso dei percettroni
Studio nr. 1 - Marzo 2025 (senza LLM)
Abstract - by Notebook LM
La pagina descrive uno studio sull'applicazione dell'intelligenza artificiale tradizionale, nello specifico i percettroni, allo sviluppo di un software per il gioco del Tris. L'autore descrive il software, scritto in Python e disponibile su github.com, che utilizza una rete di percettroni, per giocare, che può apprendere dinamicamente. Riporta la struttura del software, delle classi implementate e dei meccanismi di addestramento, sia quello iniziale basato sulle regole del gioco, sia quello successivo che evolve tramite l'esperienza delle partite. L'obiettivo è esplorare l'uso dell'AI "classica" per problemi decisionali semplici come il Tris, in contrasto con l'uso di modelli linguistici di grandi dimensioni (LLM) che verranno trattati in uno studio successivo.
1. Premessa
Nell'ambito dei miei studi sull'intelligenza artificiale (AI), sia quale passione personale che per scopi professionali, ho realizzato una piccola analisi dei metodi di applicazione dell'AI nella realizzazione di un semplice software che gioca a tris. In pratica nulla di complesso, ma è stato interessante vedere come si possa realizzare il citato software sfruttando le "vecchie" teorie dell'AI, in particolare i percettroni, per ottenere un oggetto che non solo sa le regole e gioca ma impara giocando. In una pagina successiva alla presente vedremo come lo stesso software possa essere realizzato sfruttando un LLM, ossia un modello linguistico di grandi dimensioni tipico dell'AI generativa attualmente in voga. Vedremo che i due approcci sono entrambi interessanti ma profondamente diversi. Al momento procediamo con i percettroni (inglese "perceptrons").
2. Percettroni
Il percettrone è uno dei primi modelli (matematici) di rete neurale artificiale, concettualizzato circa nel 1943. Esso è sicuramente un modello estremamente semplice e può realizzare, dal concetto di nodo, strutture più complesse quali, ad esempio, reti neurali feed-forward. In una rete di questo tipo i nodi sono connessi tra loro mediante collegamenti pesati orientati, questo vuole significare che si possono identificare input e output dei nodi e che gli output sono dipendenti dagli input mediante leggi matematiche generalmente non lineari. Nel caso in cui gli input e gli output siano dello stesso tipo, o quantomeno compatibili, è infatti possibile creare reti più complesse unendo più percettroni insieme, ad esempio usando un gruppo (o strato) di percettroni come input per un secondo gruppo di percettroni, oppure facendo in modo che l'input di ogni percettrone della rete sia dato dall'output di ogni altro percettrone (fully-connected perceptron network).
In questo lavoro impiegheremo proprio una fully-connected network con la possibilità di fare anche retroazione (non solo gli input di un percettrone sono costituiti potenzialmente da tutti gli output degli altri nodi ma il singolo percettrone ammette come input anche il suo output). Il singolo nodo (percettrone) avrà la struttura semplificata seguente:
a. un nome (stringa identificativa);
b. uno stato (un valore reale/float);
c. una soglia di attivazione (trigger level - valore reale/float);
d. una funzione di attivazione f(node1,node2,...,noden) per n nodi nella rete pienamente connessa.
In particolare, considerando lo stato Si del nodo i-esimo, si è supposto, per semplicità, che l'output Oi = Si, e quindi la funzione di attivazione sul nodo i-esimo è stata definita come segue:
fi(node1,node2,...,noden) = wi,1S1 + wi,2S2 + ... + wi,nSn+Ki
dove W = [wi,j per i,j da 1 a n] è una matrice quadrata di dimensione n che rappresenta a tutti gli effetti le connessioni pesate e orientate della rete stessa. Si tratta ovviamente di una matrice sparsa (ricca di 0) la cui manipolazione (matematica) dei pesi wi,j permette alla rete di percettroni di essere "plastica" (nel senso di cambiare forma) e di far emergere comportamenti simil-intelligenti quali apprendimento, adattamento, classificazione, decision-making, ecc.. Il valore Ki, spesso indicato con il termine "bias" è invece un valore reale che non dipende da alcun valore in input ed è associato al nodo stesso.
Ancora per semplicità, si considera che qualora il valore fornito dalla funzione di attivazione per il nodo i-esimo superi la soglia di attivazione stabilita, il nodo ni si attiva e il suo stato (quindi il suo output) si porta al valore 1.0.
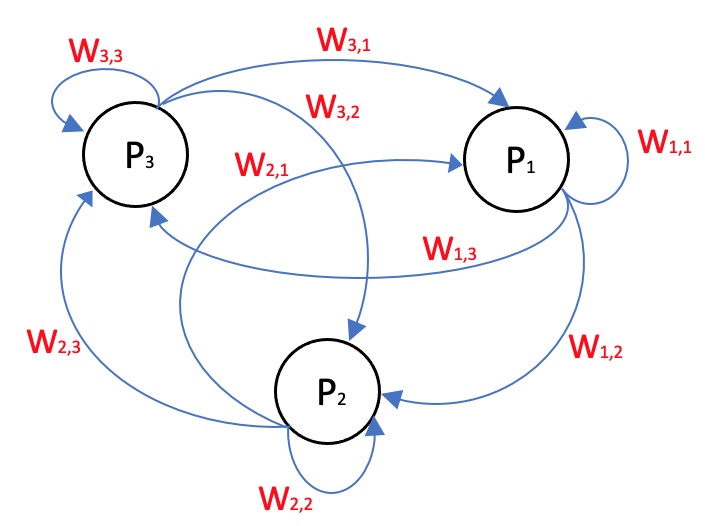
Come si può capire, soprattutto per coloro che hanno un background in materia, si è considerato un modello abbastanza semplice del percettrone e ciò per due ordini di motivi: (1) il gioco da modellare è semplice nelle sue regole (vds di seguito) e nel numero di stati che prevede; (2) una rete di questo tipo con diverse centinaia di percettroni è facilmente gestibile e programmabile con i computer attuali, anche senza ricorrere a congrue potenze di calcolo.
3. Tris (gioco)
Il gioco del tris (in inglese "tic tac toe") è relativamente semplice e noto alla maggioranza delle persone. L'area di gioco, cui spesso ci si riferirà con il termine inglese "board" o "game board", è una tabella 3x3 per un totale di 9 celle. Ogni cella ammette solo 3 stati possibili: EMPTY (cella vuota), CIRCLE (cerchio), STAR (stella o croce). I giocatori partono con una board vuota (tutte le celle in stato EMPTY) e giocano alternativamente, partendo da uno dei due mediante una selezione iniziale o un accordo/turnazione. Ogni giocatore può inserire unicamente nelle celle in stato EMPTY il simbolo (CIRCLE/STAR) univoco che gli corrisponde dall'inizio della partita. Vince il giocatore che riesce a disporre tre dei propri simboli in linea retta orizzontale, verticale o diagonale. Se la griglia viene riempita (full board) senza che nessuno dei giocatori abbia vinto, la partita finisce senza vincitore, alla pari. La partita può naturalmente finire prima dello stato di full-board.
Il motivo per cui è stato considerato il tris in questo studio è il fatto che, sebbene a seguito della sua semplicità sia altamente modellabile dal punto di vista matematico, rimane un problema di natura decisionale rilevante e tempo-indipendente. Esso è, infatti, un gioco ad informazione completa e perfetta (def. dalla teoria dei giochi), ossia ogni giocatore: (1) ha tutte le informazioni sul contesto e sulle possibili strategie dell'avversario, sebbene non ne conosca le azioni future; (2) è a conoscenza di tutte le mosse eseguite dall'avversario fino all'istante considerato. La decisione della mossa quindi, nel tris, si può far dipendere esclusivamente dallo stato istantaneo della board e non è necessario prendere in considerazione la sequenza delle mosse che ha portato i due contendenti in quella situazione (tempo-indipendente).
D'altro canto, il tris è anche un "gioco risolto" nel senso della teoria dei giochi, ossia è definita una strategia difensiva (Newell and Simon 1972 - vds par. 5 conclusivo) che se seguita perfettamente dai due contendenti porta sicuramente al pareggio. Quella che non è invece definita è una strategia d'attacco perfetta che possa portare uno dei avversari a prevalere con certezza a partire dalla mossa iniziale, fanno ovviamente eccezione i casi in cui ci sono due simboli già in fila e la susseguente cella libera (immagine di seguito) oppure i casi dei "fork", ossia le situazioni in cui tre simboli sono vicino tra loro e possono generare vittoria in due modi diversi (immagine di seguito):
Esempio di due simboli in fila, attacco su cella in giallo:
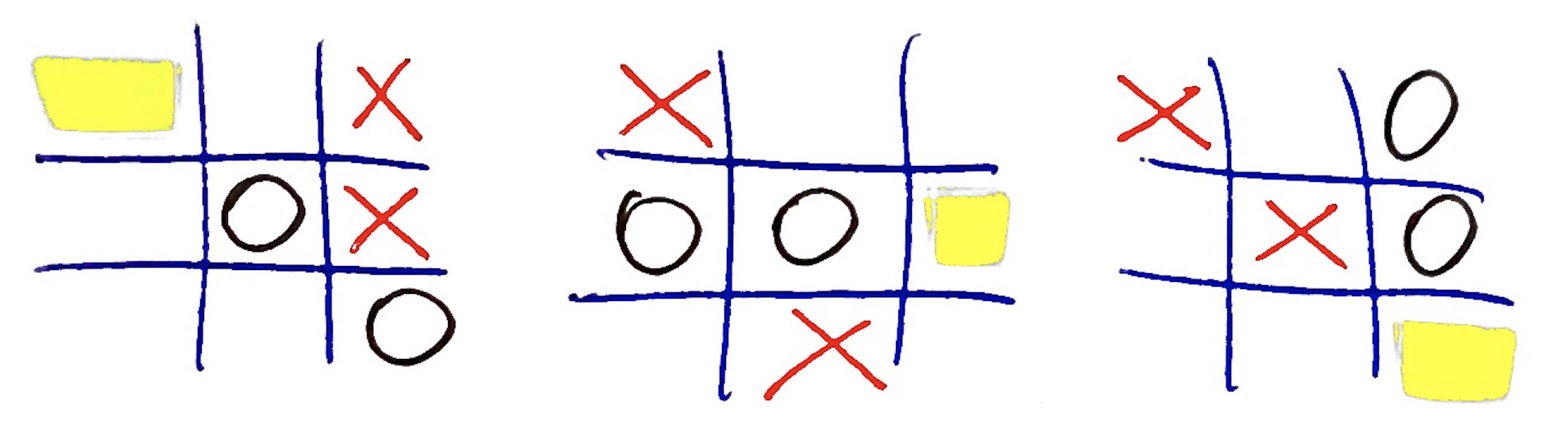
Esempio di fork, attacchi doppi su celle in giallo:
rimane quindi un esercizio decisionale interessante il tipo di strategia d'attacco e questo lavoro si occupa di incorporare sia strategie di difesa (consolidate) che di attacco nell'apprendimento di una rete di percettroni. Ciò in alternativa a considerare un classico software di gioco che considera gli alberi decisionali e quindi valuta, in maniera più o meno empirica o tramite strategie definite, una serie di percorsi decisionali per vincere.
4. Il software realizzato
Il software, riportato su github.com/mmattiucci2024/tris è a disposizione di tutti ed è stato da me realizzato in python per una questione di mera comodità. Come noto a chi mi conosce, sono un metodico strutturato, per cui il codice è perfettamente commentato, praticamente riga per riga, per cui approcciarlo, per usarlo o scaricarlo e modificarlo, è semplice. Il livello della programmazione impiegata è medio e non vengono richiamate librerie "ricercate" per cui può essere eseguito su qualsiasi interprete senza particolari predisposizioni a livello di sistema operativo. In esso, trattandosi di uno studio, si definisce tutto da zero, dal percettrone, alla rete di percettroni, fino al gioco con le tecniche di base ed infine un sistema di apprendimento automatico, gioco-durante, che fa evolvere la sua strategia. Questo programma si può usare anche da solo, senza i file da me costruiti addestrandolo giocandoci (
mytris.lessonslearnt_win.txt,
mytris.lessonslearnt_tie.txt,
mytris.lessonslearnt_not_loose.txt
4.1 Le classi
Il software è strutturato ad oggetti con le seguenti classi:
myPerceptron(
name,trigger_level = 0.9
): costruisce il singolo nodo definendone il nome e la soglia di attivazione che viene normalmente lasciata a 0.9.
myPerceptronNetwork(
name,max_nr_of_nodes
): costruisce la struttura informativa necessaria per gestire una rete di percettroni i cui nodi sono oggetti myPerceptron(). Ne definisce il nome e il massimo numero di nodi inizializzabili. La matrice quadrata W[] di collegamento pesato tra tutti i nodi e il vettore K[] dei pesi associati ai singoli nodi sono strutture dati definite all'interno della classe quali attributi. I metodi della classe permettono di: (1) inizializzare un nuovo nodo, (2) inizializzare un nuovo link pesato tra due nodi già inizializzati, (3) inizializzare insiemi di link pesati in blocco così da facilitare le procedure di addestramento della rete, (4) far evolvere il singolo nodo, ossia calcolarne il successivo stato valutandone tutti gli input ed i collegamenti mediante la funzione di attivazione che risulta embedded in questo metodo, (5) applicare il metodo precedente ad una serie di nodi.
myTris(
starting_status = [EMPTY for i in range(9)]
): costruisce un gioco base del tris da un'istanza della classe precedente myPerceptronNetwork() realizzando la game-board nei primi 9 nodi della rete di percettroni e tutta la conoscenza del gioco (statica e dinamica) nei nodi successivi. Lo stato iniziale della board è di default con tutte le celle EMPTY. Dato però che il gioco non opera sulla sequenza di azioni ma sullo stato istantaneo della board si può anche impostare uno stato iniziale non nullo (con il gioco già in corso). Questo è molto utile quando si vuole valutare la reazione del software a singole situazioni complesse della board e non a semplici mosse singole. I metodi di questa classe permettono di: (1) provare a fare una mossa sulla board, nel senso che i primi 9 percettroni della rete, rappresentanti la game-board, possono essere valutati in ordine casuale alla ricerca del primo che si attiva (che, nel caso, blocca ovviamente il processo perchè solo una mossa è consentita per giocatore alla volta), (2) resettare tutti i nodi allo stato EMPTY (valore 0.0) ad eccezione dei primi 9 (la board), questo permette alla rete di evitare errori di valutazione a causa della troppa memoria dei fatti già accaduti, (3) rispondere ad una data situazione della board, ossia data una conoscenza base di attacco, difesa, vittoria, sconfitta e pareggio, verificare cosa il software propone come prossima mossa. Va rimarcato che il costruttore di questa classe gioca un ruolo fondamentale, esso determina un addestramento statico della rete di percettroni a concetti base relativi alle regole del gioco. La classe myTris() non ha strategie di gioco particolari e nemmeno riesce ad imparare, la sua conoscenza è minima, statica e embedded nella struttura della rete (vedere nel paragrafo 4.2 come funziona l'addestramento statico).
myTrainedTris(
starting_status = [EMPTY for i in range(9)]
): questa classe è ottenuta per ereditarietà dalla classe myTris() precedente, realizzando un gioco del tris con conoscenza di base e capacità di apprendimento. Il costruttore della classe invoca quello di myTris() e poi lo estende accedendo ai file di testo che storicizzano l'esperienza di gioco (mytris.lessonslearnt_win.txt, mytris.lessonslearnt_tie.txt, mytris.lessonslearnt_not_loose.txt) ampliando la rete e fornendo un ulteriore training ai percettroni rispetto a quello di base, qualora i file non esistano o siano vuoti a tutti gli effetti myTrainedTris() si comporta come myTris(), ossia usa solo la conoscenza base. I metodi aggiunti rispetto a myTris permmettono di: (1) verificare lo stato semantico della board, ossia: vittoria di A, vittoria di B, Pareggio, Game Over, (2) ottenere la mossa del computer rispetto alla situazione attuale della board usando tutta la conoscenza possibile (sempre embedded nella rete di percettroni), (3) richiedere all'utente una mossa verificando l'accettabilità, (4) gestire il gioco tra utente e computer.
myGameLearning(): questa classe, che sfrutta al suo interno la classe myTris(), permette l'apprendimento e costruisce i file di testo sopra citati (base di conoscenza esterna al software). Al termine di una partita il software chiede all'utente se vuole che gli schemi dell'incontro siano analizzati a scopo di apprendimento. Se l'utente aderisce, questa classe usa un metodo specifico per analizzare la partita, mossa per mossa confrontando quello che entrambi i giocatori hanno fatto e quello che la classe myTris() avrebbe fatto nella stessa circostanza, ciò per valutare cosa ricordare della giocata. L'apprendimento si basa su 3 concetti: (a) mosse risultate utili in una situazione della board per attaccare e vincere, (b) mosse risultate utili in una situazione della board per difendere e non perdere (c) mosse risultate utili per non perdere arrivando a un pareggio se non si può far meglio. Si favoriscono prima le mosse che permettono di vincere, se non ce ne sono si passa a quelle che nel peggiore dei casi portano ad un pareggio, infine si considerano quelle che probabilisticamente non dovrebbero far perdere (dettagli nel paragrafo 4.2 successivo su come questo viene valutato dal sistema).
4.2 Addestramento statico (di base)
Innanzitutto bisogna sottolineare che CIRCLE = 1.0 è il simbolo associato al software, STAR = -1.0 è il simbolo associato all'utente e EMPTY = 0.0 è il valore dello stato della cella per considerarla vuota.
Ciò detto, come si è già evidenziato, conviene riconsiderare che la board del gioco è formata dai primi 9 percettroni della rete. E' infatti importante sottolineare che tutti i 9 percettroni della board sono retroazionati, ossia hanno come primo input il loro stato (ossia il loro output).
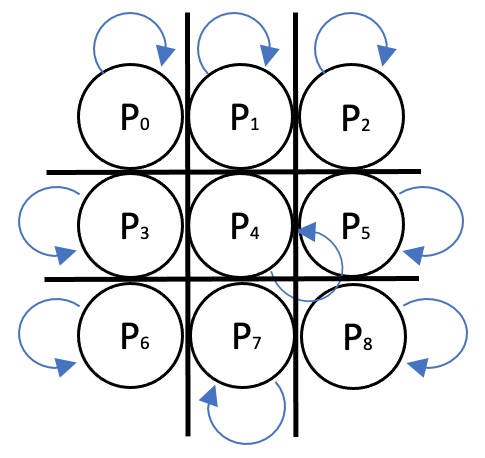
Questo in realtà è il primo addestramento statico della rete: la citata retroazione porta le celle (i percettroni) occupati con CIRCLE (ossia 1.0) e quelli con STAR (ossia -1.0) a non poter essere sovrascritti (basta provare con la funzione di attivazione cosa accade con qualsiasi tipo di input aggiuntivo). Ciò, in termini di gioco, incorpora la regola che una volta fatta la mossa su una cella non si può cancellarla (e tornare a EMPTY).
L'addestramento statico della rete di percettroni relativo alla classe myTris(), ossia dei nodi esterni ai 9 della board, è quello di base per il gioco e fa riferimento a:
- rilevazione della vittoria del software con OOO;
- rilevazione della vittoria dell'utente con XXX;
- prossima vittoria deterministica del software con OO_ oppure O_O o infine _OO;
- prossima vittoria deterministica dell'utente con XX_ oppure X_X o infine _XX;
- parità in quanto la board non ha più celle vuote e non ci ne sono 3 simboli allineati.
Dal punto di vista matematico l'addestramento che compie il metodo costruttore di myTris() è impostare percettroni e pesi di collegamento così da poter distinguere le citate situazioni. Ciò detto, se si considerano OOO o XXX basta collegare in ingresso ad un nuovo percettrone 3 link pesati 1/3 (per CIRCLE) o 3 link pesati -1/3 (per STAR) affinche questo si attivi quando si verifica la tripletta, basta infatti verificare lo schema che segue:
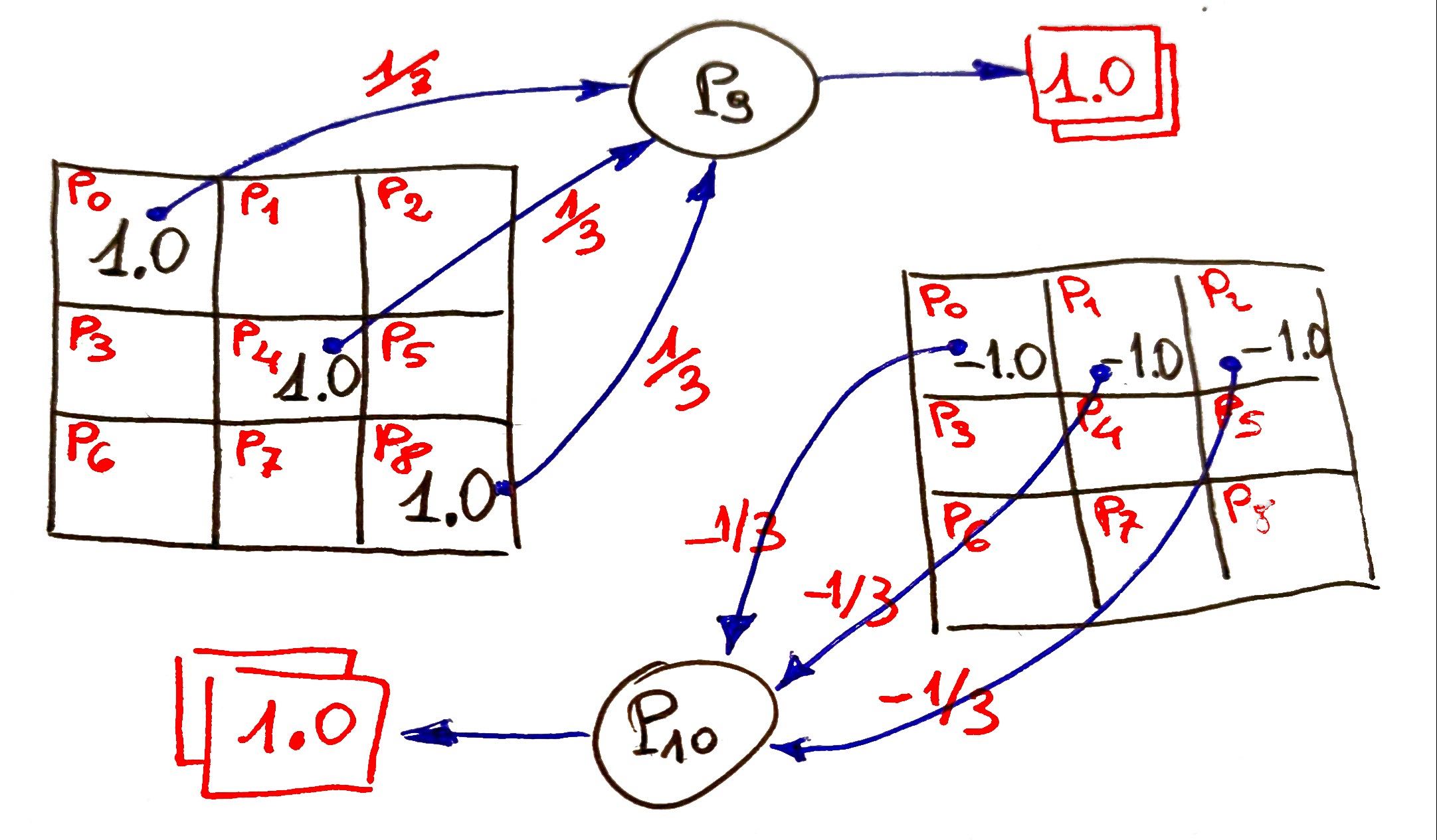
in esso il percettrone P9 si attiva solo se sulla diagonale principale della board (i percettroni 0,4 e 8) c'è una sequenza OOO, mentre il percettrone P10 si attiva solo se sulla prima riga della board (percettroni 0,1 e 2) c'è XXX. Il costruttore di myTris() inizializza collegamenti e percettroni per individuare ogni caso possibile di sequenza tripla. A questo punto se PO1,PO2,...,POn sono i percettroni che si attivano per tutte le triplette OOO e PX1,PX2,...,PXn per le XXX basta creare un secondo strato come segue per individuare di chi è la vittoria e un terzo (sempre nella figura seguente) per definire che c'è un game-over per vittoria di uno dei due:
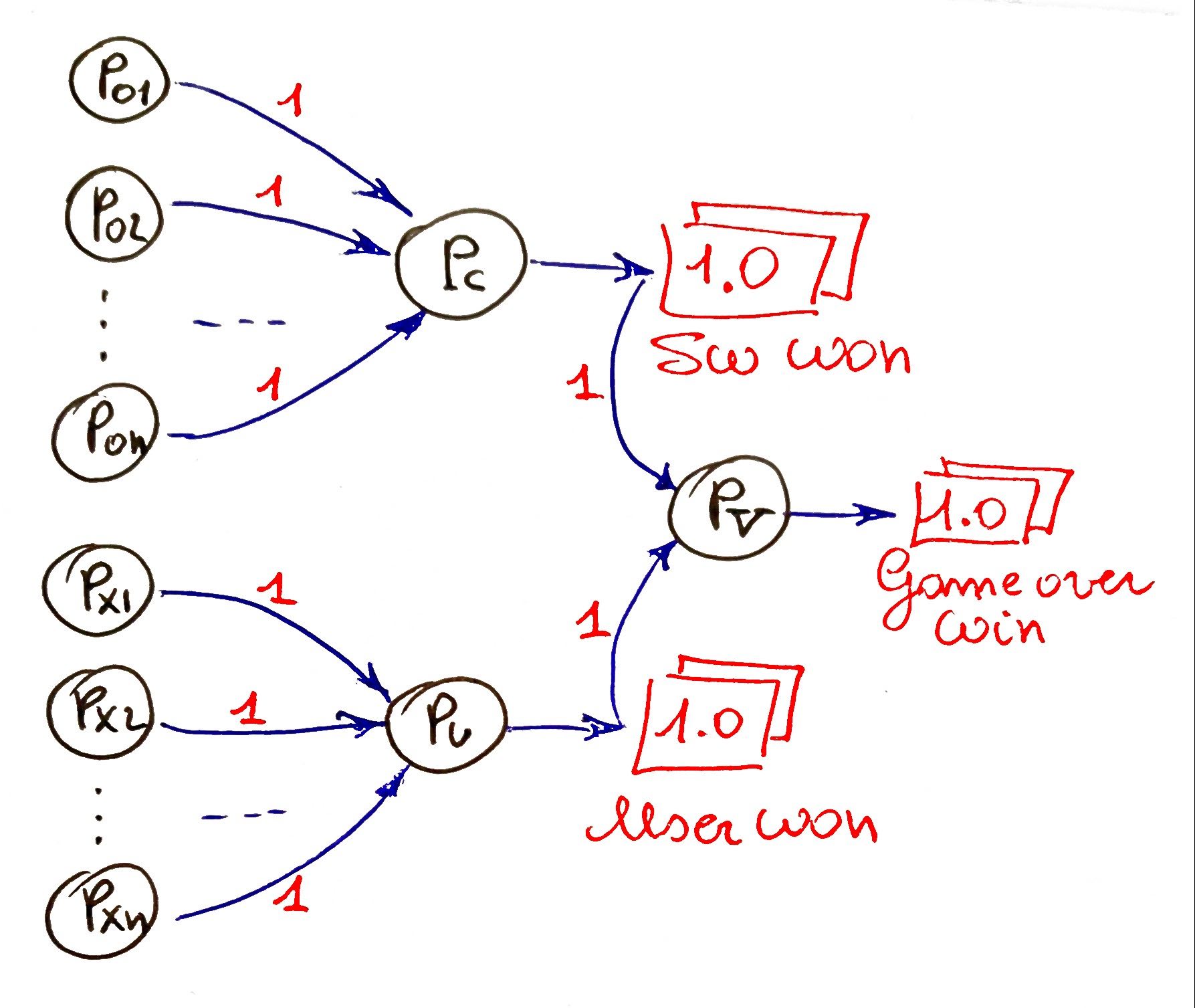
quindi, se Pc si attiva il software ha vinto, se invece si attiva Pu ha vinto l'utente, in ogni caso, se si attiva Pv c'è un game-over per vittoria di uno dei contendenti.
Altro training statico di questo tipo è stato incorporato in myTris() per gli altri punti della lista precedente. Precisamente nei punti in cui c'è la vittoria determinata del software (ossia due simboli CIRCLE in fila e la restante cella libera) o la difesa obbligatoria del software (due simboli STAR in fila e la restante cella libera) è necessario fare un'ulteriore retroazione sui percettroni della board ma a più strati:
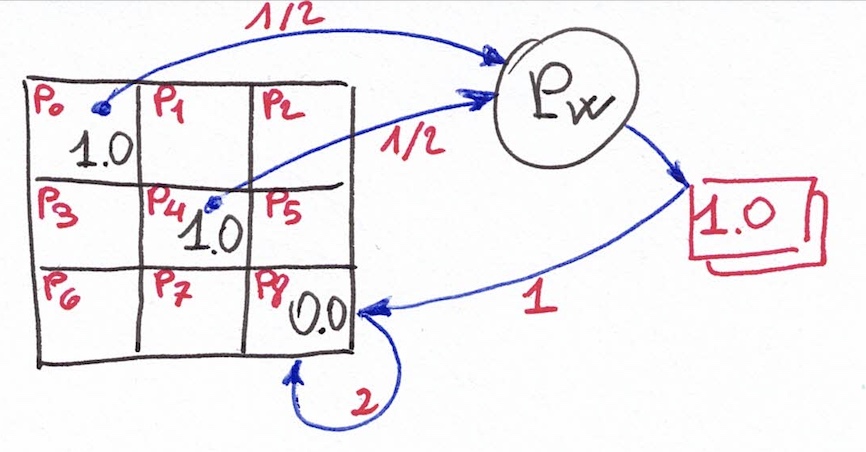
come si può vedere i due collegamenti pesati 1/2 fanno in modo che Pw si attivi solo se sulle celle 0 e 4 della diagonale ci siano 2 CIRCLE (valore 1.0). In. tal caso l'uscita di Pw è 1.0 da cui tramite il collegamento pesato 1.0 cerca di attivare la cella 8 (per completare la tripletta). Dal suo canto, il percettrone 8 è però già retroazionato direttamente sulla sua uscita per cui: (1) se è vuoto si attiva a CIRCLE realizzando per il gioco una mossa vincente; (2) se ha una STAR non si può attivare per cui l'indicazione di Pw va persa. Un meccanismo del tutto analogo a questo, ma nel quale i due pesi iniziali sono -1/2, realizza la difesa base ossia quando la rete di percettroni sente che ci sono due STAR in sequenca tenta di inserire un CIRCLE nell'eventuale cella libera (che consentirebbe altrimenti al giocatore umano di vincere).
Per la parità, ultimo punto della lista di cui sopra, l'addestramento statico è un poco articolato e si compone di 3 strati:
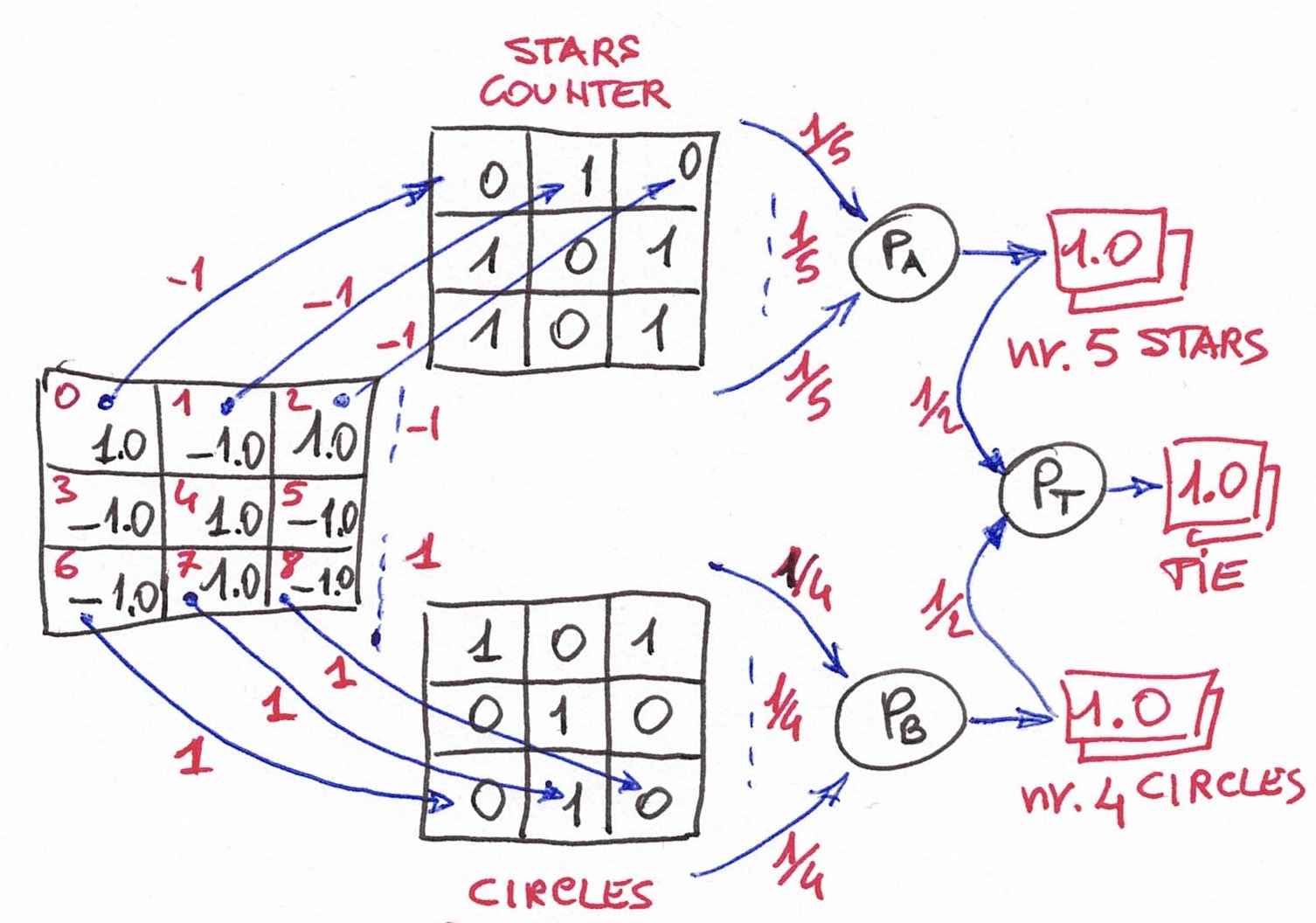
come si può vedere la board viene mappata su 2 gruppi di 9 percettroni mediante link cella a cella con peso 1.0 in un caso e -1.0 nell'altro. La prima mappatura in alto con -1.0 otterrà sostanzialmente una sorta di board-clone che conta le STAR, mentre la seconda mappatura in basso con 1.0 conta i CIRCLE. Ogni set di percettroni delle due board-cloni viene usato come input per un unico percettrone, nel caso di sopra PA e in quello di sotto PB. Dati i pesi (1/5 e 1/4) dei collegamenti si ha che PA si attiva solo se nella board c'erano 5 STAR e PB solo se nella board c'erano 4 CIRCLE. Le uscite di PA e PB fanno da input a PT che, usando i collegamenti con pesi 1/2 e 1/2 si attiva solo quando nella board ci sono 5 STAR e 4 CIRCLE e quindi un pareggio. Attenzione che quella descritta nella figura non è l'unica ammissibile situazione di pareggio, ne esiste anche quella complementare in cui ci sono 4 STAR e 5 CIRCLE, nella classe myTris() infatti gli strati descritti nella figura sono duplicati e i segni dei collegamenti iniziali invertiti per contemplare anche questo. I due nodi PT1 e PT2 (questo non è mostrato in figura) che ne risultano vanno come input a un altro percettrone PF mediante collegamenti pesati 1.0 così che quando uno dei due nodi segnala un tipo di pareggio PF è comunque attivo.
4.3 Addestramento dinamico (apprendimento)
Il software è in grado di apprendere dalle partite che svolge, ad esempio l'addestramento dinamico che gli ho fatto svolgere e che ha determinato i 3 file (mytris.lessonslearnt_win.txt, mytris.lessonslearnt_tie.txt, mytris.lessonslearnt_not_loose.txt) presenti su github è stato ottenuto facendolo giocare con il tris online di Google il quale, nella sua versione "impossibile", è estremamente efficace e difficile da battere. Naturalmente il software si può usare da zero senza i file txt che ho preparato e si può impostare un addestramento dinamico del tutto nuovo. Si consiglia un addestramento "duro" con giocatori esperti, altrimenti il rischio è che apprenda strategie deboli.
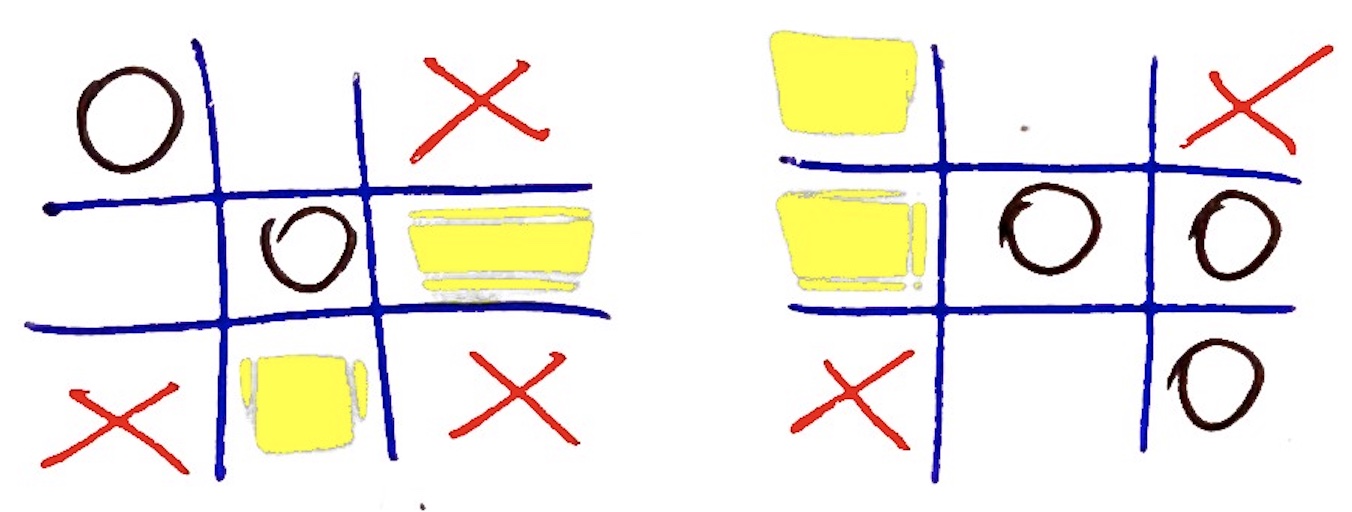
Visto che le partite sono il dato base da cui si parte per "apprendere", ossia modificare la rete di percettroni, il primo concetto da introdurre è quello di match o partita, ossia un vettore di 10 elementi in cui: (1) il primo elemento è il simbolo del giocatore che parte (CIRCLE il software, STAR l'utente) e gli altri nove gli ID delle celle occupate in sequenza considerando che i simboli si alternano. Quale esempio prendiamo quello nella figura che segue, in cui si arriva ad una vittoria:
 |
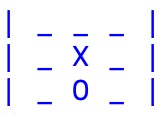 |
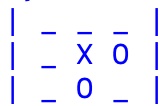 |
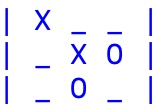 |
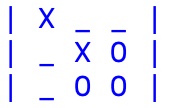 |
|---|---|---|---|---|
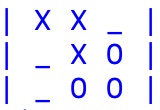 |
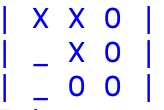 |
che si codifica come: [CIRCLE,7,4,5,0,8,1,2,None,None].
Come si può vedere il gioco finisce prima di riempire la board a causa della tripletta di CIRCLE sulla terza colonna per cui gli ultimi due elementi della codifica della partita sono nulli (None). Dato che inizia il software (CIRCLE), la 7 è occupata da CIRCLE, la 4 da STAR, la 5 da CIRCLE, ecc. fino alla fine, questo chiarisce come viene costruito il descrittore delle partite.
Se l'utente abilita il software ad apprendere a fine partita, questo verifica innanzitutto se ci si trova di fronte ad una vittoria di uno dei due giocatori o a un pareggio. Nel caso dell'esempio è una vittoria del software per cui esso ritiene che le mosse fatte siano "buone". Vengono quindi analizzati tutti i contesti della board nella partita e le relative mosse fatte dal vincitore, in pratica:
| Contesto | Stato finale | |
|---|---|---|
|
mossa: CIRCLE in cella 5 -> | |
| Contesto | Stato finale | |
|
mossa: CIRCLE in cella 8 -> fork tra 2 e 6 |
|
| Contesto | Stato finale | |
|
mossa: CIRCLE in cella 2 -> Vittoria del sw |
|
Come si può notare la mossa finale in 2 è una mossa già imposta dall'addestramento statico per cui sarebbe ridondante apprenderla, questo, in caso di vincita di uno dei due è una consuetudine. La mossa iniziale in 5 può essere appresa ma naturalmente la sua utilità è discutibile perché potrebbe portare ancora a risultati diversi la partita. La mossa centrale in 8 è invece fondamentale perchè genera una fork, ossia una situazione senza uscita in cui il software vince per forza, questa mossa, quindi, è molto importante da apprendere. In generale le mosse centrali sono determinanti nell'apprendimento. Il software, nello studio di una vincita, considera le mosse iniziali poco importanti e spesso ma non sempre sostituibili con mosse casuali, le mosse centrali come determinanti da apprendere in dettaglio, soprattutto se myTris() risponde a tale contesto con mosse diverse o casualmente, per chiudere, quelle finali le delega alle regole statiche già presenti in myTris().
L'apprendimento, in concreto avviene in questo modo: il software estrae tutte le mosse di una partita, seleziona quelle da apprendere e programma i collegamenti di un percettrone che riesca a riconoscere il contesto della board e la cui uscita va verso la mossa considerata buona. Di seguito un esempio per la prima mossa di cui sopra:
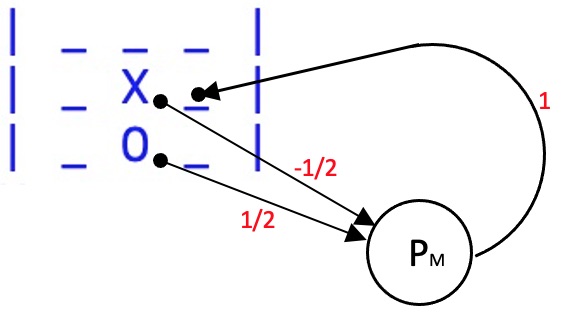
I percettroni 4 e 7 della board entrano in PM con pesi -1/2 per STAR e 1/2 per CIRCLE così da riconoscere tali simboli in tali posizioni, l'uscita di PM va nella cella 5 della board con peso 1 ad eccitare tale percettrone per svolgere la mossa qualora il contesto sussista (ovviamente funziona solo se la cella 5 non risulta già occupata - ricordare la retroazione diretta sui percettroni della board non riportata in figura per non creare confusione).
Accanto a questo processo di identificazione di mosse probabilmente vincenti vi è anche la valutazione opposta, di mosse che possono portare velocemente alla sconfitta. Il software esamina quindi la stessa partita con "occhi" opposti, quelli di colui che ha perso e con lo stesso processo di prima individua le mosse questa volta da evitare. Senza entrare troppo nel dettaglio (essendo la cosa molto simile a quanto già visto), nel caso precedente l'utente (STAR) ha sbagliato la mossa in 0 perchè ha così permesso la fork. Il software si accorge di questo e per quel contesto impone randomicamente una mossa diversa da 0.
| Contesto | Stato finale | |
|---|---|---|
|
mossa: STAR in cella 0 -> errore da evitare |
|
L'ultima parte dell'apprendimento dinamico riguarda il caso di pareggio, esso viene analizzato come nel primo caso (vincita del software) ma le mosse che se determinano vengono usate dal software solo se non se ne può fare a meno (meglio il pareggio che perdere).
In questo modo il software, partita dopo partita determina e riempie 3 file di testo con le modifiche da fare alla rete di percettroni per addestrarla dinamicamente prima di ogni partita. I file sono 3 proprio in riferimento a:
(a) contesti e mosse appresi come da fare in caso di vincita, quindi plausibilmente per vincere;
(b) contesti e mosse appresi come da non fare per evitare plausibilmente la sconfitta;
(c) contesti e mosse appresi come da fare per pareggiare, quindi plausibilmente per evitare di perdere quando non si può più vincere.
5 Conclusioni
Un software classico per il tris, assolutamente compatibile con la strategia perfetta di Newell and Simon (1972) si può trovare su github.com/WesleyyC/Tic-Tac-Toe con tanto di documentazione. "Classico" intende che i meccanismi di implementazione della strategia sono rigidi e fatti di codice di programmazione python, nessuna AI è coinvolta. Lo scopo di questo studio, invece, è applicare due tipologie di AI allo stesso problema, il gioco del tris, plurianalizzato negli anni, ciò per capire le differenza di approccio. In questo caso sono stati usati i percettroni, in una prossima pagina vedremo come usare gli LLM per risolvere lo stesso problema.
Per finire va considerato che il software appena descritto, ad un'analisi anche superficiale, evidenzia il massimo sforzo nella realizzazione della rete di percettroni e nel suo addestramento, non ci sono particolari oneri di programmazione lato python per il flusso del gioco, tutto è in carico ai percettroni ed ai loro collegamenti. Nel software di Wesleyy appena citato tutto lo sforzo è nel codice python che implementa flusso e strategie insieme. Uno dei principali effetti di questa osservazione è che migrare il software che ho realizzato in C++ o altri linguaggi a oggetti non è affatto complicato, in quanto non fa molto riferimento ai meccanismi propri del linguaggio di programmazione.
Alla prossima pagina dove avremo la parte 2 dello studio, stavolta con gli LLM...
Cookie(s) & Privacy
Questo sito web, per quanto da me programmato e realizzato in php, non emette cookie, non effettua il profiling dell'utente e non raccoglie vostri dati personali. Alcuni cookie possono essere emessi dal cloud che lo supporta, strumento al di fuori della possibilità di controllo dello scrivente. Per qualsiasi dubbio in proposito smettete immediatamente la navigazione.marcomattiucci.it
Informatica:
Intelligenza artificiale:
- Home(AI)
- AI forte
- AI debole
- AI distribuita
- AI sociale
- Singolaritá
- La Logica
- AI e Leggi
- AI ed Etica
- Tris parte 1